


#42 - Onion Routing, Markus the LNM 🐳, downside incoming? and much more

⚔️ LNM Fam
🏆 There has been a fierce competition for the meme award this week with a lot of potential winners (@jesperolsanajek, @AndrejCibik, @ThordVoldemort, @gegelsmr2, etc.). Congrats @Griptoshi for bringing the big trophy back home, we had a big laugh on this one!

Speaking of whales, we heard while we were in El Salvador the crazy story of the host of the biggest Bitcoin podcast in Germany opening big positions on LN Markets during his show. Finally a decent explanation for our popularity there? His name is @MarkusTurm. This LNM whale has become so big that he even has his own parody account!

Markus is also member of the Einundzwanzig community, an association of German-speaking Bitcoiners which make tutorial on YouTube, run podcasts, meetups, conferences, etc. All the money they make from that supports projects and developers in the space! "Einundzwanzig" is German for 21 and they now even have communities in other countries like turkey which follow their approach: a decentralized Bitcoin community.
We were curious to know more about the man behind the myth. Thanks for Markus for your testimonial 🙏🏻
“I'm part of one of the largest german Bitcoin community “Einundzwanzig”, for our new Youtube channel I wanted to make a short tutorial about LNMarkets, Dennis from BTCpay said I should go 5x long with 500,000 sats, otherwise it would be boring.
So I did that, but the morning after the broadcast an unusually large number of people made fun of me in our chat groups. It was the day after Tesla announced it would no longer accept Bitcoin, so my sats were all gone. Since then the whole thing has turned into a running gag, people ask me for trading tips just to take the opposite position.
Every time there are major movements in the market, they suspect me behind them. If they want the price to go up they ask me to go long on LN Markets so the market would do the opposite. They call me a bitcoin whale now and run parody accounts on twitter, it got so crazy that my wife found out and asked me if we are really that rich. I think i made LNMarkets really famous in germany, people even ask me for help if they have problems on LN Markets.”
🏆 Degen of the week is @ThordVoldemort. Thanks for his hilarious thread!



🚨 And rejoice dear frens, we have a new release coming very soon™️ with cool features you might like!

📊 Binance traders expecting downside?
The long/short ratio at Binance suggests that a majority of the Binance accounts
are net short at the moment.
The long/short ratio illustrates the proportion of net long and net short accounts
to total accounts with positions. Each account is only counted once. A long
account is defined as an account with net long exposure and vice versa.
The open interest in these markets is always net neutral. However, it is interesting
to understand the current consensus trade to reflect on its implications in the
leveraged market.

Currently, the long-short ratio in the most popular bitcoin derivative, the
stablecoin collateralized perp on Binance, is sitting near all-time lows at 0.743,
meaning that a majority of the accounts with exposure in the perp is currently net
short.
Leverage in the market remains high. The open interest in the BTCUSDT perp on
Binance is sitting near all-time highs when denominated in BTC.
Before last summer's short squeeze, the long/short ratio sat below 1. Sentiment
remained muted until the October rally, when the ratio began to surge towards
the long side.
Interestingly, as highlighted in the chart, before the April 18th, May 19th,
November 26th, December 4th, and January 5th sell-offs, the long-short ratio
surged above 4. By monitoring the long/short ratio, you may get opportunities to
de-risk ahead of turmoil.
The long/short ratio at Bybit also hints that a majority of the Bybit accounts are
net short. This, alongside the futures basis and funding rate, suggests that the
sentiment among derivatives traders remains bearish at the moment.
The crowd at Binance and Bybit have been wrong numerous times before. Will this time be different?
👉 Get full access to Arcane Research’s Weekly Update here.
🤔 Onion Routing

This article is the first (out of two) concerning Onion Routing. It is also the first of the Routing Series, where I'll try to cover in depth how routing works in the Lightning Network, and how it could work differently (ever heard this story about an ant jumping on a trampoline?). This article is an introduction to Onion Routing, and offers a "high level" view of how it works. The second article will go deeper into the inner workings of Onion Routing in the Lightning Network.
In a previous article about PTLCs, I emphasised that a very important feature of the Lightning Network is being able to send payments to nodes you are not directly connected to, by routing the payment across the channels of other nodes. Indeed, if this wasn’t the case, the Lightning Network would barely deserve the “network” qualifier.
To send a payment across the network, it is therefore necessary to be able to find a route and to follow it. This article will not deal with the ways a Lightning node can compute routes between two points across the network (a process usually called pathfinding), but with the second part: having the payment follow this route, from its emitter to its recipient, and through all necessary intermediary nodes.
There are plenty of ways to do just this, like I’ll exhibit in a first paragraph. The method in use today on the Lightning Network, called Onion Routing, aims at enhancing the privacy of the network’s users, by hiding the source and destination of a payment to the intermediary nodes involved in the route.
Packet routing in the internet
Data on the internet is transmitted in “packets”: little chunks of data, going from one source computer to one destination computer, and passing through a few intermediate routers along the way. In the (very) early days, source routing (where the emitter is in charge of computing the whole route) was feasible, but the internet uses nowadays a far more efficient, fault tolerant paradigm: packet switching.
In packet switching, the sender of the packet isn’t responsible for the calculation of the whole route to its destination. Instead, they attach a header to the packet, which states the address of the destination. The sender then sends the packet to a router, which is a special computer built for the sole purpose of routing packets. The router looks at the address in the packet header. If it doesn’t know this address directly, it then sends the packet to another router which, according to the information available to him, might know the address (or know another router that knows this address, etc.). Within a few hops, the packet will be in the hands of a router that knows the destination address, and will send it directly to the corresponding computer.
You can think of it as of postal sorting centers (also called processing and distribution centers in the US). After collecting the mail, postal operators bring it to such centers. There, mail is either directly dispatched to the destination address if it falls within the geographical “jurisdiction” of this specific center, or sent to another center.
When you use your computer to access the internet, all of this happens behind the scenes. Let’s consider you, right now, reading this article. You may have accessed it from Twitter, or from the wonderful LN Markets newsletter (are you subscribed?), or even because you searched for “onion routing” on your favourite search engine. Either way, you clicked a link, and it brought you here. What happened is you sent a request to the server hosting this website, and it replied by sending some html back to you.
Your computer sends the request to your internet box (the one provided by your ISP), with the address of this website server attached.
Your box usually forwards it to one big router belonging to your ISP.
This router looks up the address. If it corresponds to the same ISP, the router will have the address in its “directory” and send the packet directly to the server. Else, the router will be able to find in its directory which ISP this server is attached too, and then send the request packet to a router belonging to this ISP.
The router of the other ISP will look up the address in its own “directory” and find the server, to which it sends the request.
The server then responds in the same way: by sending packets of data with your address on the envelope.
Of course, this is greatly oversimplified. I didn’t mention your box ports, the MAC addresses of the various devices, the way multiple packets corresponding to the same user interaction can follow different routes, nor how the server’s address was derived from the domain “fanismichalakis.fr”. But this simplified version is far enough for the purpose of explaining the differences between source routing and packet switching.
Packet Switching vs Source Routing
What we see from this example is that your computer didn’t have to compute the whole route for your packet. Instead, it just sent it to your ISP’s router (via your box), letting the router find the next hop in the route. The router then either found the server directly, or forwarded the packet to another router which it believed would know the server ; and so on. Each hop is in charge of choosing the next one, with the goal of making the packet arrive in a timely manner and without too many hops. But for this to work, each hop must know the address of the final recipient of the packet (in order to be able to determine which hop to send the packet next), as well as the emitter of the packet (in order to route the server’s response back to it). It’s quite efficient, but not very privacy preserving: everyone involved knows where a request originated and where it was headed to.
That’s why Lightning engineers opted for a different approach, with a certain kind of source routing called “Onion Routing”. Source routing only means that the source node is in charge of computing the whole route ; onion routing refers to the fact that each intermediary node only has access to a very limited set of information – the bare minimum for it to perform its tasks.
Onion Routing
In Onion Routing, the node emitting the payment computes the whole route leading to the destination (eg., through which channel the payment should go in order to reach the recipient). Then, it encapsulates this information in successive encrypted layers, so that each intermediary node only knows which node came before in the route, and which node comes next. I will go into more detail as to how this layering works exactly in the next article, but let’s first cover the journey of an onion-routed payment.
Let’s take an example with 5 nodes: Alice, Bob, Carol, Daniel and Eve. Alice sends 20,000 sats to Eve ; and Bob, Carol and Daniel are intermediary routing nodes. For the sake of simplicity, we’ll assume all the routing nodes charge the same fee of 1,000 sats [1].

Alice starts by sending Bob a message, encrypted so that only Bob can read it. Bob opens (eg. deciphers) it and finds 2 sections: one he can read and which contains instructions, and another that is unintelligible to him because it is encrypted with a key he doesn’t have. The part Bob can actually read tells him to send a HTLC(22,000, r) to Carol, along with the second section of the message (the one that is still encrypted). In exchange, Bob will be able to claim a HTLC(23,000, r) from Alice once he learns r [2].
As the reader may have already guessed, this second portion of the message is encrypted with a key that Carol has. She is therefore able to open it and, just like Bob, she finds 2 sections: one she can read and one encrypted with another key. The readable section tells her to forward 21,000 sats and the still ciphered section to Daniel.
The second portion of Carol’s message is of course encrypted with Daniel’s key. He opens it and find 2 sections as well. The readable one tells him to send the encrypted one to Eve, along with 20,000 sats.
We can represent the whole process as follows, where “For Bob” means that Bob can read the text below ; while the ~ represents text he can’t decrypt.
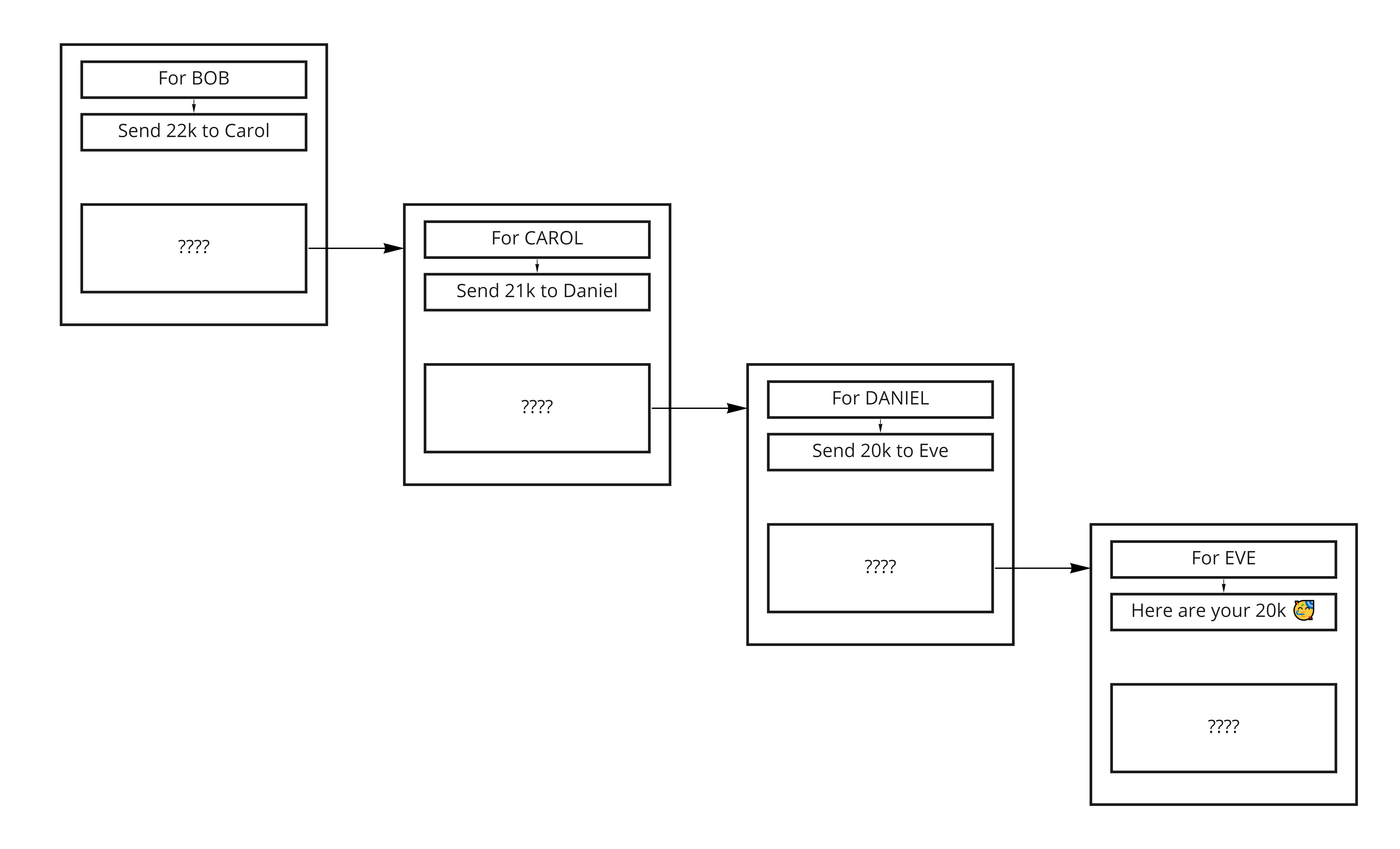
Another representation could be:
For BOB: Send 22k to Carol
For CAROL: Send 21k to Daniel
For DANIEL: Send 20k to EVE
For EVE: Tada! 🥳 Here are your 20k.
This way, each node along the route can only read the amount he must transfer to the next hop in order to be able to claim what was conditionally sent to him by the previous node. Successive messages are hidden behind layers of encryption, which are removed one by one at each hop, just like one peel an onion from its successive layers. When Bob receives the first message from Alice, he has no way of telling wether Alice is the emitter of the payment, or if she’s just sending him the second section of a message she just received from someone else. Likewise, Daniel doesn’t know the content of the message he’s sending to Eve, and hence he doesn’t know if she’s the final recipient or just another hop. And of course Carol, in the middle of the path, has no more clue than them.
It might come to the mind of the reader that nodes may be able to somehow guess their position in the route by the weight (in terms of bytes) of the data they transfer. Indeed, the encrypted message Bob sends to Carol contains not only Carol’s message, but Daniel’s and Eve’s as well ; whereas Daniel’s message to Eve only contains Eve’s message. To prevent this, random bytes (it’s called padding) are added at the end in the encrypted messages, so that they all weight the same. That’s why all the boxes in our diagram have the same size.
The Limitations of Onion Routing
Onion Routing comes with some inefficiencies, in its effort to try to protect the privacy of users. Some of this inefficiencies are linked to the Source Routing aspect (it’s no wonder we don’t use it for internet traffic anymore) ; others come from the Onion dimension.
First, because the sender must take care of computing the whole route, their node must keep an up-to-date map of the network, large enough to allow him to reach a great portion of the network. Such maps inevitably become bigger and bigger as the network grows. This process, called graph synchronisation, can be quite heavy, notably for mobile nodes, which therefore increasingly tend to rely on third party nodes for route computation. If we don’t take care of this, we might find ourselves in the same situation as with the internet, where in the end, only specific, purposely tailored machines hold the “full” graph of the network and are responsible for computing routes. From a quite decentralized network, we’d end up with an heavy dependance on Lightning Service Providers.
Second, in order for Onion Routing to actually work, nodes must gather the information about other nodes' channels, so that they can build the topology of the network and find routes through it. This is performed by having nodes gossip to each other about the announced channels they are aware of. In other words, to achieve some level of privacy (hiding sender and recipient) and decentralization, we rely on the repeated sharing of information across the network. Too often, node operators aren’t completely aware of the implications of announcing their channels to the network: it links the UTXOs used to open the channels with the node public key, which is known by anyone seeing an invoice generated from said node. To put it in a nutshell: Onion Routing is currently far more decentralized than Packet Switching, is quite private for sender and receiver, but requires a ton of information to be made public in order to work efficiently.
Moreover, even with all this information made public, the exact repartition of funds at any given time between the two parties of a channel remains known only to them. Only the capacity of the channel is shared with the network. While this is desirable on the privacy aspect, this leads to some serious inefficiencies: a node can’t be sure wether the liquidity on a distant channel is in the right side of the channel for the payment to be successful. All it can do is try to guess which route has the best chances to work, and retry until the payment succeeds or all routes have failed. With Packet Switching, the situation would be very different, as each hop would decide where to send the payment next with the knowledge of where the funds are in their channels. This is not to say Packet Switching is better (it is not), just a highlight of this key difference. In the end, what matters is wether the inefficiencies caused by Onion Routing are worth it regarding the privacy it allows to achieve (once again, I recommend this article on PTLCs which deals precisely with this subject).
Another thing to consider is that, because of Onion Routing, if a routing node decides not to forward the payment (by not creating the required HTLC), there’s no way for the sender to know where the payment failed, or why. That’s why there is a set of error messages detailed in the specification of the Lightning Network, that routing nodes are expected to send to the emitter if they can’t forward the payment (for example, because their liquidity is depleted). But a malicious actor could withheld payments for some time without sending error messages (although it would probably lead to this node being avoided by pathfinding algorithms over time).
Of course, those limitations don’t mean we should throw Onion Routing away. Like everything, it has its pros and cons. The problem of keeping a detailed, up-to-date map of the network I mentioned earlier is actually still quite manageable today for nodes running 24/7 on consumer grade hardware such as Raspberry Pis. But it was worth mentioning them, as they are key to understanding why alternative approaches are being investigated.
TL;DR
Two nodes can exchange value on the Lightning Network even if they are not directly connected with a channel. If required, payments can indeed travel through other nodes' channels. The route of a payment is computed by the sender of the payment, which passes encrypted instructions to the routing nodes on the route. These instructions are built and encrypted in such a way that any given node on the route only knows which node came just before and which node comes next. This design obfuscates the identities of the sender and recipient of a payment, but comes at the cost of some inefficiencies.
By Fanis Michalakis, Bitcoiner & Techno Padawan @LNMarkets
[1] For example, a base fee of 1,000 satoshis and a 0% fee-rate. A bit unrealistic but let’s keep it simple.
[2]If you don’t know what HTLCs are, I encourage you to read my article on PTLCs, where I also describe HTLCs ; or to watch this video I made one year ago on the subject. Here is a three sentences summary if you’d rather continue reading this article first: HTLCs are conditional Bitcoin payments where the sender commits to sending a certain amount on the condition that the recipient can provide a certain secret. HTLC(22,000 , r) means a conditional payment for 20k sats where the condition is the revealing of a secret s such that hash(s) = r. It is therefore equivalent to writing HTLC(22,000 , s). HTLCs are used in Lightning to temporarily “lock” funds in the channels of a route until the payment either completes or fails – they are usually not published on the Bitcoin blockchain, unless a channel is closed while a payment is still in-flight.
⚡ Bonus
🍿 Our favourite show running for 13 years now

⚡ Funny cause it’s true

🧡 Lyn is always right

🤝 Reach out on Twitter, Telegram and Discord to build the future of trading together!